

The big idea of generative models
An interface to the adjacent possible

If hypertext was the big idea of the internet, what is the big idea of generative AI?
First, possibility space. Possibility space is the abstract space containing all possible permutations of something. For example, the possibility space of 2D images contains every possible combination of pixels, and thus every possible 2D image. The possibility space of books contains every possible combination of letters, and thus every possible book.
In Why greatness cannot be planned, Stanley & Lehman ask us to consider this space as a room.
Imagine this giant room in which every image conceivable is hovering in the air in one location or another, trillions upon trillions of images shimmering in the darkness, spanning wall to wall and floor to ceiling. This cavernous room is the space of all possible images. Now imagine walking through this space. The images within it would have a certain organization. Near one corner are all kinds of faces, and near another are starry nights (and somewhere among them Van Gogh’s masterpiece).
Creativity, then, is a search problem. Everything already exists, and creation is a process of searching through the room. Stanley and Lehman again:
…we can think of the process of creation as a process of searching through the space of the room… In this way, artists are searching the great room of all possible images for something special or something beautiful when they create art.
As you discover new parts of the room, it becomes easier to see new areas that haven’t been explored before. Previous ideas build on each other to reveal new possibilities.
As you can imagine, the kind of image you are most likely to paint depends on what parts of the room you’ve already visited… As we explore more and more of it, together we become more aware of what is possible to create. And the more you’ve explored the room yourself, the more you understand where you might be able to go next.
At any given point in the room, there are pathways in both directions. You have always come from somewhere, and so there is always a historical context extending backwards. Looking forwards, there is a set of future possibilities that depend on where you’ve come from. Stuart Kauffman calls this forward direction the adjacent possible.
Given the historical context, the adjacent possible represents all the currently available ‘next steps’. It fractures off in many branching directions, with each possibility birthing yet more possibilities. Moving through this space is a process of continuously selecting a branch.

There’s something very deep about this idea. The best ideas tend to pop up in multiple places, and this one appears everywhere.
Evolutionary biologists can think of the possibility space of traits as a fitness landscape, or the possibility space of shapes and forms an organism can take as a morphospace. AI researchers can think of the loss function of an algorithm as making up a loss landscapes. — Gordon Brander (Possibility Space)
Arguably, we can think of every creative domain in this way. Whatever the medium, there is always a space of possible forms that already exists as a potential. The job of a creative process is to discover the “good” ones, by exploring the space and selecting the desirable paths.

Exploration and selection through the space of all possibilities appears even at the fundamental level. The universe itself is as an open-ended creative process through the space of all possible universes. Starting from a set of fundamental particles, the universe continuously makes ‘creative decisions’ that select a pathway out of all possibilities.
Depending on how you interpret this, some suggest that there isn’t just one universe. Rather, all the possible universes exist simultaneously and we simply find ourselves in one of the infinite branches. This is, of course, a thoroughly weird idea and it is beyond my technical capabilities to discuss with any sophistication. But critically, it suggests that possibility space is an insight into the fundamental nature of reality.

To review the key points:
Possibility space contains all possible permutations. All permutations already ‘exist’ — creativity is about exploring and selecting the desirable ones.
The adjacent possible describes the subset of available moves given everything that has happened in the past.
These ideas seem fundamental. We can look at all creative domains in this way whether its making movies or making universes.
Possibility spaces might seem esoteric and complicated. That is part of the problem — it is complicated for humans to comprehend. The true number of moves inside the adjacent possible is bewildering, and it takes an extraordinary amount of imagination to see even a small subset.
But I wanted to drive home how fundamental this idea is because if we could somehow unlock the adjacent possible through an abstraction that humans can understand, then it would be obviously important. It would be like unlocking a direct mapping of the creative process, and possibly the fabric of reality itself.
Perhaps you see where this is going. I’m going to argue that AI will be that abstraction, and this is the big idea that must be understood about this technological generation. Navigating possibility space is to AI as hypertext was to the internet — the fundamental creative leap that sits at the core of what AI unlocks for humans.
Generative models directly represent the adjacent possible
To see how, I need to make sure that everyone is on the same page. The idea is clearest with language models, so let’s quickly review the basics of how they work. If you already know how they work, I promise this won’t take long.
Language can be broken down into words. Words can be broken down further into parts of words. Language models work because they become very good at understanding how parts of words relate to each other in a given context. Based on that understanding, they can generate language in new contexts while adhering to all its implicit rules.
When you pose a question to an LLM, like “What is art?”, the model takes that input and constructs a probability distribution that determines what the most likely next word is (really the most likely part of a word, but let’s just stick with words here). Then, it will take a sample from that distribution, where the chances of retrieving each word are weighted by its probability.

Each time a new word is selected, it gets added on to the input. The model then restarts the process with the new input. It repeats this over and over again until the sampled ‘word’ indicates that it is time to end the output.

The idea I want to focus on here is that each time the model selects a new word to add onto the sequence, there is a distribution of possible choices. One word was chosen, but it could have been multiple others. Sometimes, there are many possible words that could have fit in the same slot. In others, only a few fit. In others still, one word is so overwhelmingly likely that only one word fits.
Since the new word gets added onto the input for the next round, the eventual outcome is determined by which words get selected along the way. Instead of a linear sequence, the process looks more like this:
At each node in the tree, there is a backwards and a forwards direction. In other words, a past and a future. The words available in the future direction depend on what words were chosen in the past.

This looks familiar. Recall Tim Urban’s graph from earlier:

The tree is possibility space. From the point of view of each word, language models see the adjacent possible directly — that is, all the next words that could make sense given the input. During inference, they ‘explore’ this space and select the next word by probability.
This is what makes generative models creatively new. They don’t just see one possibility — they see all the future possibilities simultaneously and rank them by probability.
This idea becomes important when you scale up the size of the model and the size of the dataset.
Today, the datasets are so big that they approach all the data created on the internet, which approaches all the data ever created. Going back to the graph, the datasets represent an increasingly significant proportion of our ‘history’. In other words, all the things we learned on our journey through possibility space into the present.

Meanwhile, the models are now so big that they are very good at inferring the rules that are implicit inside ~all the things we’ve learned so far. Their internal representation of the adjacent possible represents an increasingly significant proportion of the actual adjacent possible — that is, all the (sensible) future possibilities inside a domain given our collective history.
What makes the good models good is that they are better calibrated at understanding which paths are worth exploring.

A good intuition of what this means comes from Jorge Luis Borges. In 1941, he created the idea of the Library of Babel. It contains every possible book that can be expressed in language. Since books have no terminal length, the number of possible books is infinite. The library is another instance of possibility space.
The Library is total… its shelves register all the possible combinations of the twenty-odd orthographical symbols (a number which, though extremely vast, is not infinite): Everything: the minutely detailed history of the future, the archangels' autobiographies, the faithful catalogues of the Library, thousands and thousands of false catalogues, the demonstration of the fallacy of those catalogues, the demonstration of the fallacy of the true catalogue, the Gnostic gospel of Basilides, the commentary on that gospel, the commentary on the commentary on that gospel, the true story of your death, the translation of every book in all languages, the interpolations of every book in all books.
The problem with the library is that it is infinite. The vast majority of the books are gibberish and you could waste ~infinite time trying to find the good ones. Wherever you stand inside the library, there is only a small subset of paths inside the adjacent possible that actually lead to good books.
Powerful language models are like directions to all the good books. That is what makes them creatively interesting — it is not about “automation”, as such. As the models get better, it is about making the entire library explorable.
More technically, it is about representing the adjacent possible directly.

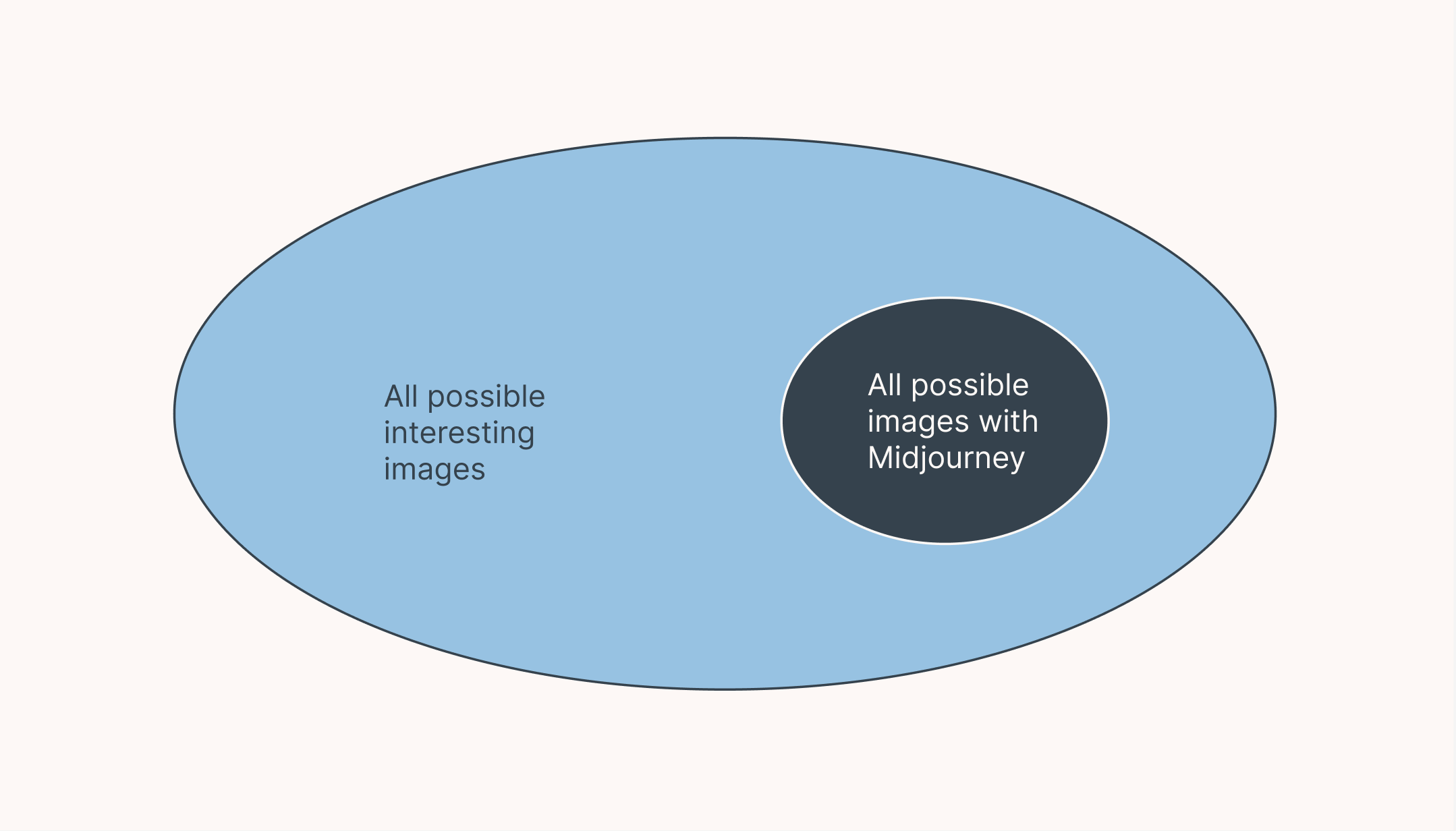
We can think of Midjourney in a similar way. The dataset approximates all the images ever made in the past. The model is a representation of ~all the images that are possible given ~all the images made in the past.

When we interface with generative models, we gain access to the ~entire space of interesting possibilities given the ~entire history of a domain.
As they improve, they are increasingly an abstraction of possibility space itself.
Of course, there are a few reasons why this isn’t quite true in reality. Today’s best LLMs are architecturally limited to thinking a single step ahead. It’s also questionable whether today’s models are really “creative”. That is, there are possibilities inside of the adjacent possible that can’t be reached by the current mechanism. For example, today’s models probably can’t invent a new artistic style, nor can they make a new scientific discovery.
Even if they are “creative”, their abilities are destroyed by RLHF. Training models on human feedback closes off large areas of the adjacent possible because they don’t adhere to a set of guidelines.
In some sense, RLHF removes precisely what makes generative models actually interesting. It’s like the Library of Babel is Hogwarts and almost all the books are in the restricted section — it’s hard to do magic when you can’t learn the spells. The power is in the base models because they represent a high proportion of the adjacent possible.


I think it is best to assume that we are early in the trajectory of AI, and that these problems are fixable. This “non-creative” phase of AI, if it exists, is temporary and we will think of better alignment methods than RLHF. The models will get better, the datasets will get bigger and the result will be to uncover more of the actual adjacent possible.
As such, I think this is the right mental model. Representing the adjacent possible is what makes generative models creatively interesting. They take something abstract and hard to comprehend and make it comprehensible to humans.
I think this is the big idea of this generation. It’s important because when you think of models in this way, you end up with a new kind of interface that is built to exploit it.
AI-native interfaces exploit the big idea
Today, most AI-first interfaces work on a linear (and frankly, annoying) call-and-response paradigm. You ask the model for a solution, and it mostly provides you with a single option (or a small few). Perhaps you workshop the response a little, but it does not recognise what makes generative models uniquely interesting.

I recently discovered Loom, a ‘multiversal tree-writing interface’ for language models made by Janus and friends. Loom is the closest I’ve seen to an AI-native interface, and the seed that inspired me to write this post. Loom’s core insight is that models enable recursive exploration of possibility space.
Through that insight, Loom explores language models with threads that represent the tree of possibilities directly. Outputs build on each other and the idea is to prune the bad ones leaving only the most interesting. That’s where the name comes from — in the same way that a loom weaves threads into a cohesive garment, Loom weaves threads into a cohesive output.
It gives you all the moves you would expect in a tree.

Critically, checkpoints are retained to be used again later. If a path doesn’t work out, just return to an interesting checkpoint and generate new paths that preserve the original context. Everything is treated as a node that can be forked in a new direction, whether that is single words or large sections.
Loom dispenses with the idea of linearity. It doesn’t force you to accept the first output you are given, and doesn’t place a bad output into the context window to influence all the future outputs. It understands the big idea, and respects generative models for what makes them creatively valuable. They are imagination engines that reveal all the pathways you couldn’t have otherwise thought of.
The beauty is that through Loom, we are afforded the ability to explore ~all the pathways. At every point, you can branch off in ~all the interesting directions to see where the pathway leads. If you don’t like where it leads, you can rewind back to the last place that was interesting and take a different route.
This is ideal human-AI collaboration. It’s more than just being able to generate outputs automatically — it’s about generating all possible interesting outputs for a given input and weaving the best ones into the eventual artefact.
Alphago is a clear example of why this is important.
Go can be represented by a tree of possible moves. It’s a complex space, but it’s not that complex — the space of all possible Go moves is nothing like the space of all possible images or all possible books. So, it was a good domain for early AI.
During the game against Lee Sedol, Alphago’s “move 37” was a revelation. Alphago saw the space of possible moves directly, including a move that no human had seen before. In turn, Go players learned a new way of thinking about the game, and everyone got a little smarter.

Alphago can be seen as an imagination tool that feeds back on human players to elevate their understanding. Loom is like this, but in the space of language rather than Go. At every node, it reveals the space of possible moves. In doing so, it reveals all the moves that were otherwise invisible, inspiring new creative directions.
Loom is just a language model interface today, but it is the seed for something much more general. It’s core mechanism works regardless of the medium, because it directly represents the underlying tree of possibilities and thus recognises what makes generative models creatively unique.
AI-native interfaces look like Loom-for-X. Loom for images. Loom for videos. Loom for memecoins and Loom for bolognese variants. You get the idea.

There is some evidence of these ideas emerging in other domains. For example, Jordan Singer’s prototype grounds image models in a context, and uses a pencil to explore the surrounding area. Checkpoints are saved over successive generations, and can be revisited if you end up somewhere undesirable. A future version might treat every checkpoint as a branch, and combine the best aspects of each branch into the final artefact.
Today, of course, there are computational limitations. Exploring the adjacent possible is best with a fast feedback loop, where there are no practical limits on the number of permutations. This is just about possible in 2D images as the above video shows, but we can’t do this in domains like video yet. It’s too expensive and it takes too long to generate one permutation.
But eventually, the questions that a generative AI-native interface should answer are:
What are all the paths available to me here?
If I chose this path, where would I end up?
If I made a different decision back there, what would be different here?
I don’t like where I am. Can I restart from the last place that was interesting?
The future of co-creation
When you look at generative models this way, the future is extraordinarily bright. The first important step is that it places humans where they belong — at the centre of a feedback loop. AI is an imagination tool that reveals the true space of possible moves. The goal is to construct a system that feeds that imagination back onto humans.

That’s particularly exciting because generative models are going to expand to cover every possible medium. That means generative models for “digital” mediums like language, images and video, of course. But we’ll also have generative models for physical mediums like chemistry, biology and manufacturing.
This is very likely because ultimately, all mediums are made of parts. Chemistry is made of atoms which are combined together to make elements and compounds. Biology is made of subsystems which are combined together to make living systems. Manufacturing is made of yet bigger subsystems that are combined together into products. Generative models are good at understanding how parts fit together, and using that knowledge to explore the space of possible forms implied by that understanding.
If current progress is anything to go by, we will find a way to integrate the mediums together. Language becomes interchangeable with chemistry, biology, manufacturing, images, video etc. GPT-10VCBM. As this happens and models become truly “creative”, their “imagination” gets closer to the actual adjacent possible.
In the limit, this is part of what superintelligence means — the ability to see close to all the possible moves. Superintelligence is what exists in the limit of imagination.

However, superintelligence doesn’t “own” possibility space. It is inherently shared because it already exists independently of any representation.
The goal of Loom and its descendants is to make that space comprehensible to a human. If we get the interface right (and we get alignment right), then the result is that we inherit super-imagination. We get close to direct access to the actual adjacent possible across mediums.
Best of all, we don’t have to understand the gory details. We don’t need to know exactly how the atoms fit together or exactly how the pixels fit together. We get to navigate possibility spaces — all possible videos, all possible proteins, all possible organisms — with human-friendly, high-level intentions.